
Presentation / Installation
Bodyformer: Semantics-guided 3D Body Gesture Synthesis With Transformer
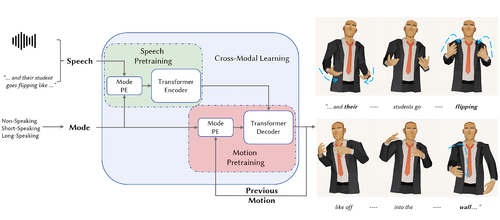
DescriptionThis paper presents a new variational transformer framework for synthesizing 3D body gestures driven by speech. The system uses a mode position embedding and intra-modal pre-training to learn motion patterns from limited conversational data. Extensive studies show that the system can generate realistic and diverse gestures similar to the ground-truth.
Event Type
Technical Paper
TimeMonday, 7 August 20232:11pm - 2:22pm PDT


LocationPetree Hall C
ACM Digital Library
Technical Papers pdfs
Session Time & Location
Research & Education
Livestreamed
Recorded
Animation/Simulation
Artificial Intelligence/Machine Learning
FC
FCS
V
VS
EFC
